
Attention工作机制
1. 前置
💡 注意力机制(Attention Mechanism)是一种在深度学习中被广泛应用的技术,它模拟了人类的注意力机制,使得模型可以在处理序列数据时更加关注重要的部分。
2. Attention
2.1 Embeddings理解
NLP中,将Words Sequences转换为Token,然后将Token转换为Embeddings.
嵌入向量通常具有以下特点:
维度固定: 在一个给定的嵌入空间中,每个符号都会被映射为固定维度的向量,这个维度可以是预先设定好的,也可以通过训练数据自动学习得到。
语义相关: 相似的符号在嵌入空间中的向量表示也会更加接近,即相似的单词在嵌入空间中的距离较近。
上下文感知: 嵌入向量的取值会受到符号所处的上下文环境的影响,从而能够表达出不同语境下的含义差异。
嵌入向量的作用:
降维: 将高维的离散符号表示映射到低维的连续向量空间中,降低了特征表示的维度。
语义信息: 通过嵌入向量,可以捕捉到单词之间的语义关系,使得模型能够更好地理解文本。
特征表达: 嵌入向量可以作为其他模型(如分类器、回归器等)的输入特征,从而帮助模型学习更好的表示和进行预测。
在实践中,嵌入向量通常是通过训练神经网络模型来学习得到的。通过在大规模文本语料上进行训练,模型可以学习到单词或字符的语义特征,并将其编码为固定维度的嵌入向量。
总之 Embedding是一种将离散符号映射到连续向量空间的技术,通过嵌入向量,可以将文本数据转换为可以被深度学习模型处理的形式,并且能够捕捉到单词或字符之间的语义关系和重要性。
因此Embedding可以看做是采用一堆数字来对每个Token的有意义的表示. 如图 
而对于语言模型来说,是对人类层次的理解,分别独立的处理tokens是难以做到语义理解的,还需要理解tokens之间的关系.如图

在 Self-Attention 中,tokens 之间的关系表示为概率分数. 每个 token 分配最高的分数给其自己,基于相关性给于其他 tokens 分数.
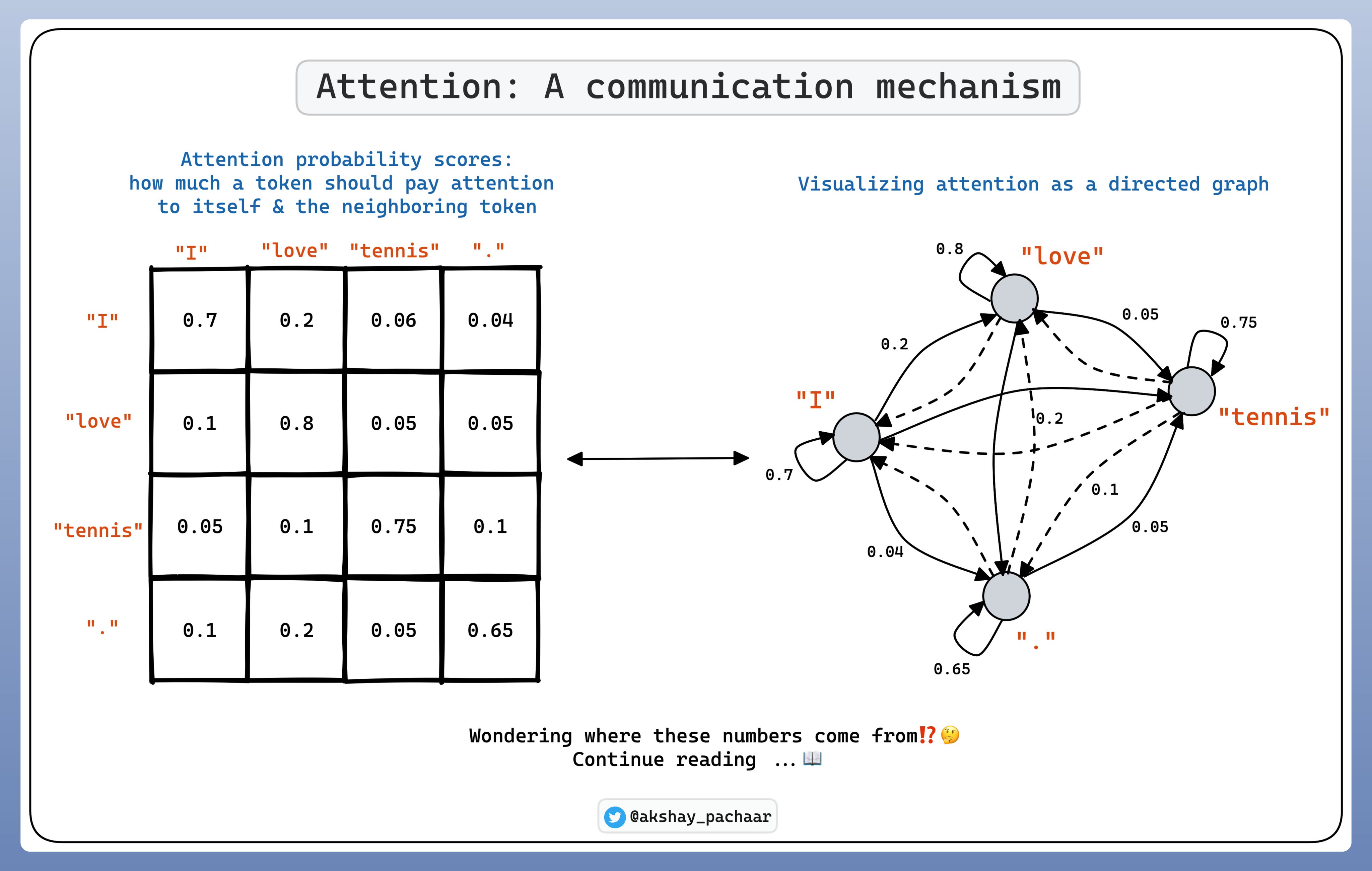
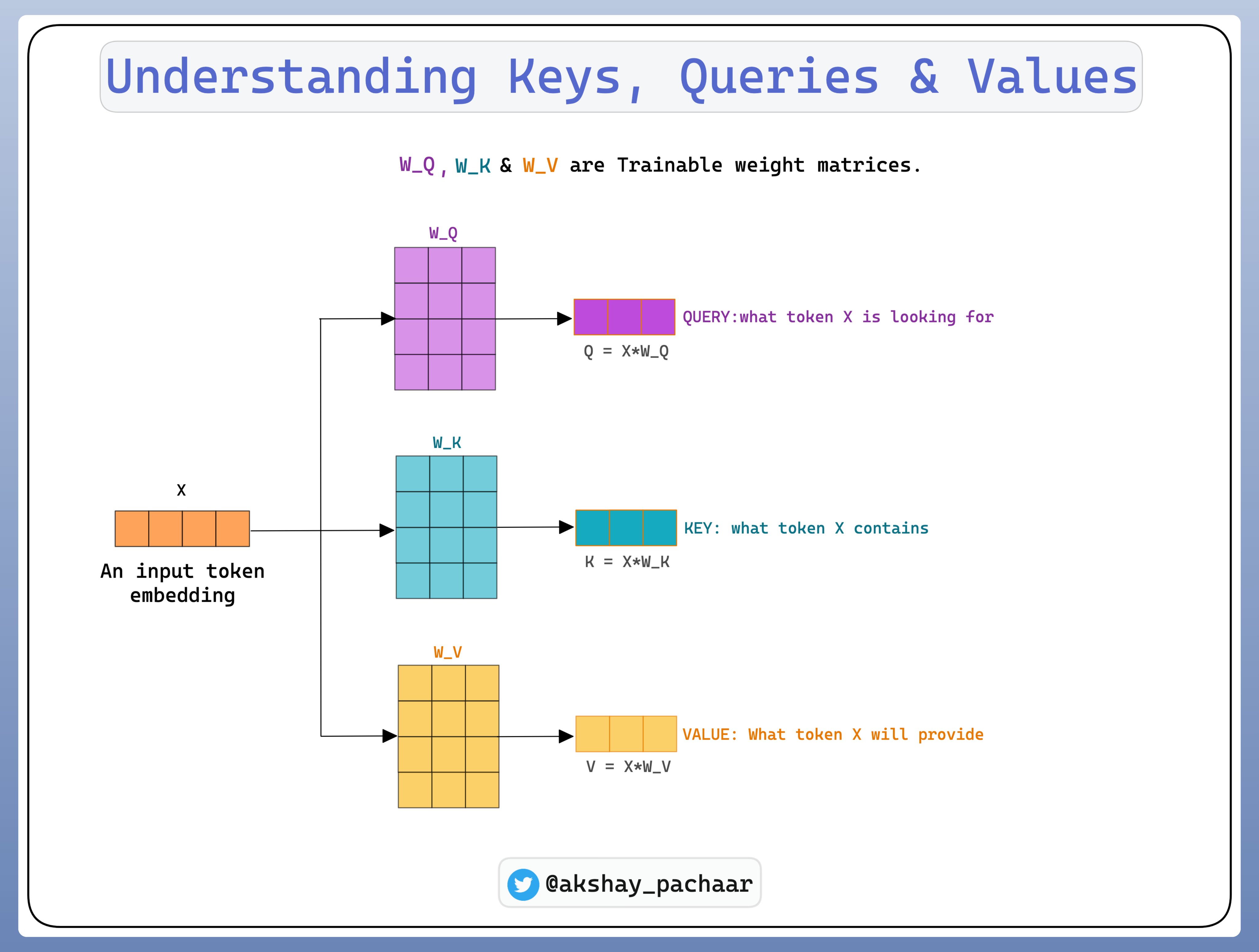
为了理解 self-attention 是如何进行的,首先需要理解三个概念:
Query Vector
Key Vector
Value Vector
这些向量是通过对 Input Embedding 乘以三个可训练的权重矩阵来得到的.
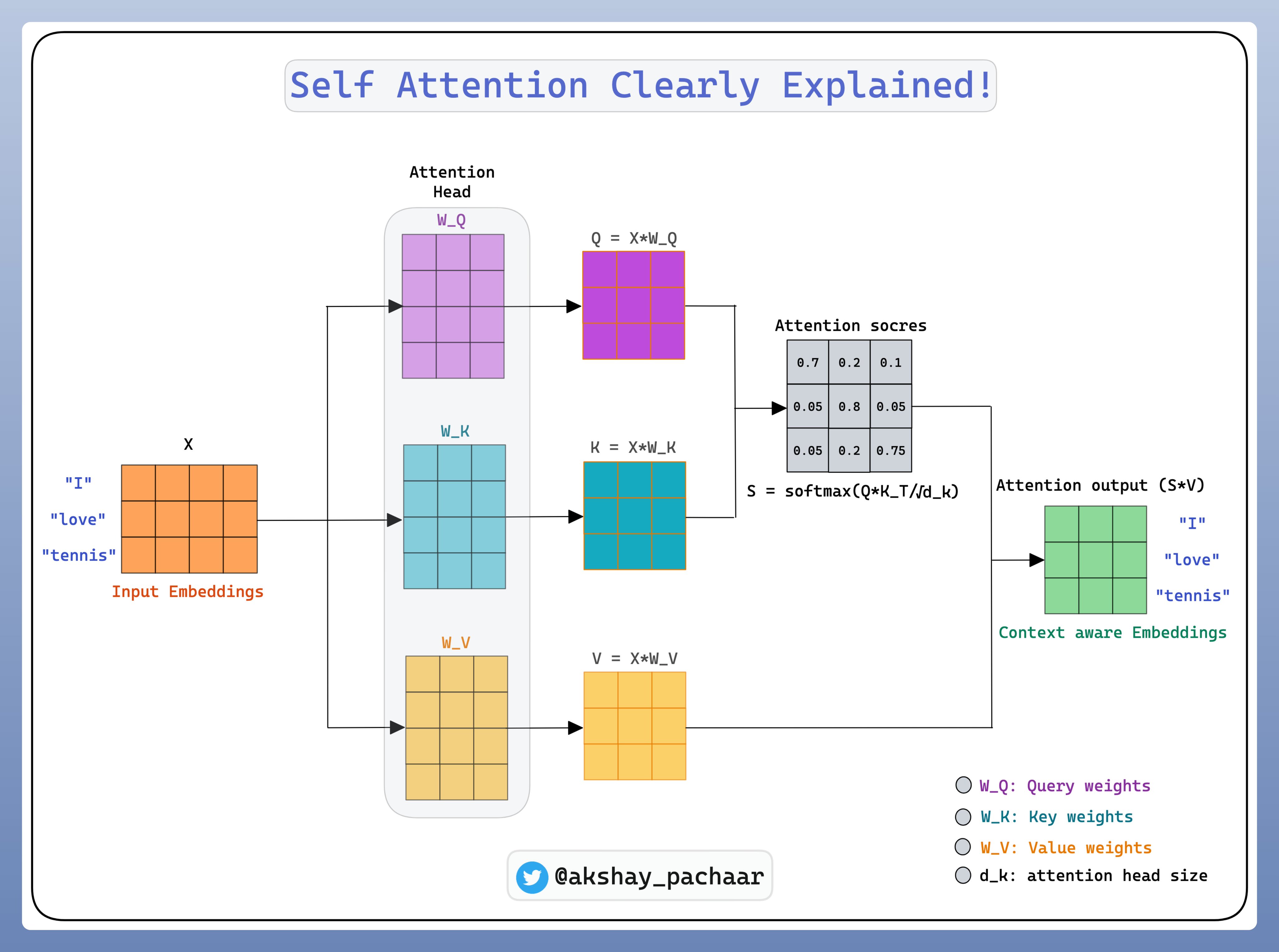
Self-attention 可以让模型学习到序列中不同部分之间长范围的依赖(Long Range Dependencies).当得到 Keys, Queries和Values 之后,将其合并一起,以创建新的Context-Aware Embeddings集合.
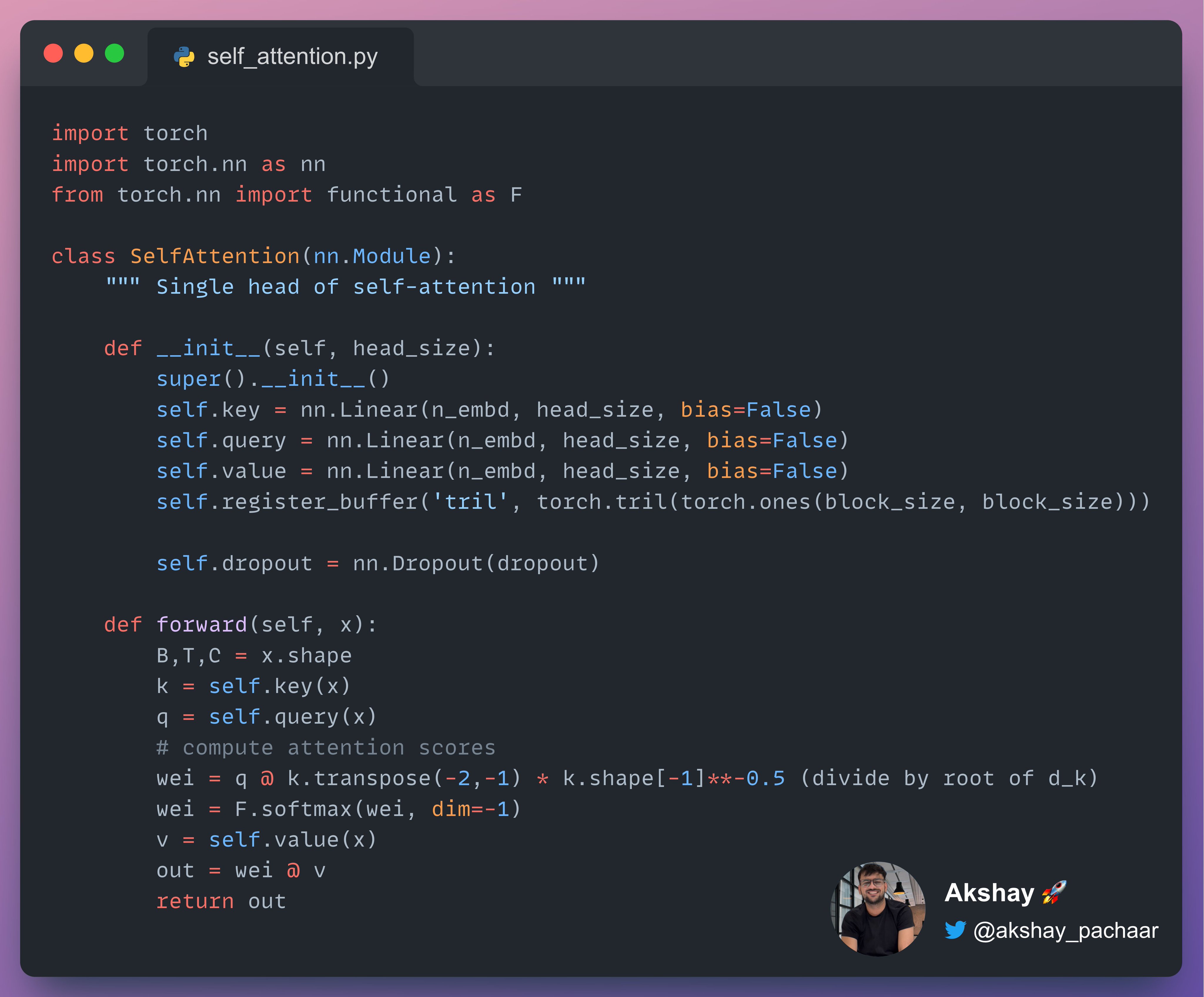
PyTorch 中 Self-Attention 的实现示例如:
在PyTorch中,还可以使用torch.nn.MultiheadAttention模块来实现Self-Attention(自注意力)机制, 以下是简单的demo演示:
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(SelfAttention, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim=embed_size, num_heads=num_heads)
self.linear = nn.Linear(embed_size, embed_size)
self.layer_norm = nn.LayerNorm(embed_size)
def forward(self, inputs):
# 计算Self-Attention
attended_output, _ = self.attention(inputs, inputs, inputs)
# 残差连接和Layer Normalization
residual = inputs + attended_output
normalized_output = self.layer_norm(residual)
# 前馈神经网络
output = self.linear(normalized_output)
return output
上述代码中,定义了一个名为SelfAttention的自注意力模型。
首先: 在模型的初始化函数中,使用nn.MultiheadAttention定义了一个多头注意力层,其中embed_size表示输入的嵌入维度,num_heads表示注意力头数。在前向传播函数中,通过调用self.attention对输入进行自注意力计算,得到attended_output。
接着: 将输入与attended_output进行残差连接(element-wise相加),然后使用nn.LayerNorm进行层归一化操作。
最后: 将归一化后的输出通过一个全连接层self.linear进行映射,得到最终的输出结果。
attention的这个简单朴素的想法,在推荐系统、时序模型,应用也比较广泛。现阶段推荐系统、时序模型领域内一般新模型都会在语言模型上去做迭代,成功之后会引入推荐模型、时序模型中。
当然在实际使用中,还需要根据具体任务场景和模型结构进行适当的调整和扩展。此处仅提供了一个简单的示例介绍一下attention机制,供简单理解和学习。
5. 参考文档
图片转载引用twitter: https://twitter.com/akshay_pachaar/status/1657368551471333384