
LSTM的输入与输出
1. 前置
💡 LSTM算法在时序预测领域应用比较广泛,LSTM本质上是在原有全连接神经网络的基础上,增加了一个时间轴的概念,同样的数据,不同的输入顺序,会得到不同的结果。这样的效果天生适合处理跟时序有关的数据。在实际使用过程当中,LSTM神经网络输入输出究竟是怎样的呢?
2. LSTM理解
2.1 LSTM模型参数含义
LSTM(长短期记忆网络)是一种循环神经网络(RNN)的变体,专门设计用于处理序列数据。相比于传统的RNN,LSTM能够更好地处理长期依赖关系,避免梯度消失或梯度爆炸等问题。LSTM的核心思想是引入了称为”门”的机制,包括输入门、遗忘门和输出门,以控制信息的流动和记忆的更新。
LSTM单元结构: LSTM单元由以下几个重要的组件组成:
1. 输入门(Input Gate):控制是否将新的输入信息纳入到细胞状态中。
2. 遗忘门(Forget Gate):控制是否将旧的细胞状态保留下来。
3. 细胞状态(Cell State):负责存储和传递信息。
4. 输出门(Output Gate):控制最终输出的信息。
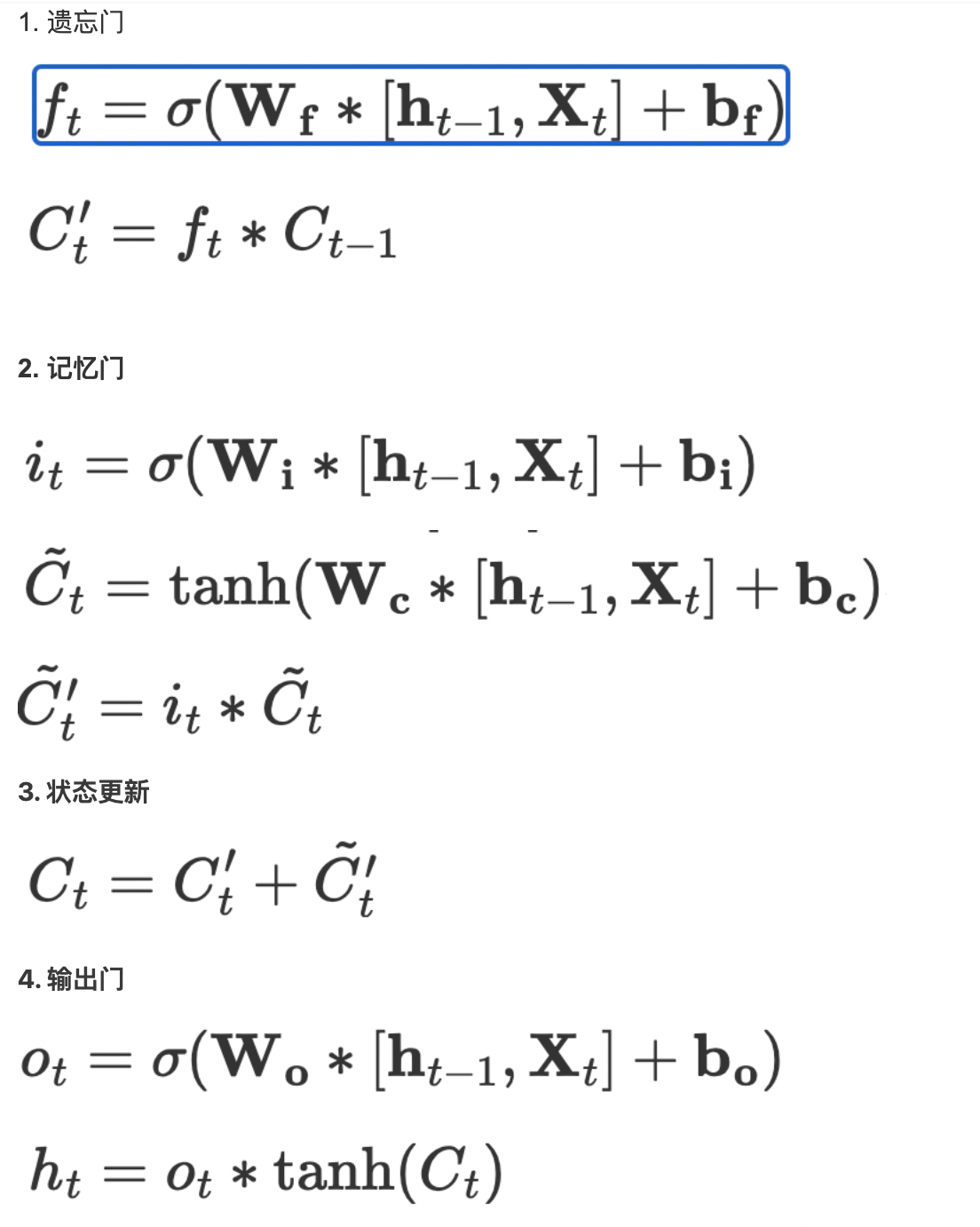
LSTM单元工作流程: 下面是一个LSTM单元的工作流程:
步骤1:输入门决定了哪些信息需要更新到细胞状态中。它通过使用Sigmoid激活函数来生成一个0到1之间的值。接下来,将当前的输入和先前的隐藏状态作为输入,通过一个全连接层来计算输入门的输出。
步骤2:遗忘门决定哪些旧的细胞状态需要被保留下来。它也使用Sigmoid激活函数生成一个0到1之间的值,控制旧细胞状态的保留程度。同样,通过一个全连接层计算遗忘门的输出。
步骤3:细胞状态更新根据输入门和遗忘门的输出来更新当前的细胞状态。首先,将输入门的输出乘以当前的输入,得到一个候选细胞状态。然后,将遗忘门的输出与先前的细胞状态相乘,得到需要被遗忘的部分。最后,将两者相加得到新的细胞状态。
步骤4:输出门决定LSTM单元的最终输出。它通过使用Sigmoid激活函数和Tanh激活函数来生成一个0到1之间的值和一个-1到1之间的值。将当前的输入和先前的隐藏状态作为输入,通过两个全连接层分别计算输出门的两个部分的输出。最后,将这两个部分相乘得到最终的输出。
LSTM通过以上的过程来实现对序列数据的建模和记忆,从而能够处理长期依赖关系。
演示: 以下是使用Python和PyTorch库来演示LSTM的简单实现:
import torch
import torch.nn as nn
# 定义一个简单的LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size)
def forward(self, input):
output, (hidden, cell) = self.lstm(input)
return output, hidden, cell
# 创建一个输入序列
input_seq = torch.randn(5, 3, 10) # 输入序列长度为5,batch大小为3,特征维度为10
# 创建LSTM模型
input_size = 10
hidden_size = 20
model = LSTMModel(input_size, hidden_size)
# 输入序列到LSTM模型中
output_seq, hidden, cell = model(input_seq)
# 打印输出结果
print("Output Sequence:")
print(output_seq)
print("\nHidden State:")
print(hidden)
print("\nCell State:")
print(cell)
3. Pytorch源代码参数理解
3.1 LSTM模型参数含义
通过源代码中可以看到nn.LSTM继承自nn.RNNBase,其初始化函数定义如下
class RNNBase(Module):
...
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0., bidirectional=False):
需要关注的主要参数以及其含义解释如下:
input_size – 输入数据的大小,也就是前面例子中每个单词向量的长度
hidden_size – 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数
num_layers – recurrent layer的数量,默认等于1。
bias – 偏置 Default: True
batch_first – 默认为False,也就是说官方不推荐我们把batch放在第一维,这个CNN有点不同,此时输入输出的各个维度含义为 (seq_length,batch,feature)。当然如果你想和CNN一样把batch放在第一维,可将该参数设置为True。
dropout – 如果非0,就在除了最后一层的其它层都插入Dropout层,默认为0。
bidirectional – 如果为True, 双向LSTM. Default: False
输入数据
输入数据需要按如下形式传入 input, (h_0,c_0)
input: 输入数据,即上面例子中的一个句子(或者一个batch的句子),其维度形状为 (seq_len, batch, input_size) seq_len: 句子长度,即单词数量,这个是需要固定的。当然假如你的一个句子中只有2个单词,但是要求输入10个单词,这个时候可以用torch.nn.utils.rnn.pack_padded_sequence()或者torch.nn.utils.rnn.pack_sequence()来对句子进行填充或者截断。 batch:就是你一次传入的句子的数量 input_size: 每个单词向量的长度,这个必须和你前面定义的网络结构保持一致
h_0:维度形状为 (num_layers * num_directions, batch, hidden_size): 结合下图应该比较好理解第一个参数的含义num_layers * num_directions, 即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的bidirectional决定,如果为False,则等于1;反之等于2。 hidden_size: 隐藏层节点数 c_0: 维度形状为 (num_layers * num_directions, batch, hidden_size),各参数含义和h_0类似。 当然,如果你没有传入(h_0, c_0),那么这两个参数会默认设置为0。
输出数据
output: 维度和输入数据类似,只不过最后的feature部分会有点不同,即 (seq_len, batch, num_directions * hidden_size), 这个输出tensor包含了LSTM模型最后一层每个time step的输出特征,比如说LSTM有两层,那么最后输出的是,表示第二层LSTM每个time step对应的输出。
另外如果前面你对输入数据使用了torch.nn.utils.rnn.PackedSequence,那么输出也会做同样的操作编程packed sequence。对于unpacked情况,我们可以对输出做如下处理来对方向作分离output.view(seq_len, batch, num_directions, hidden_size), 其中前向和后向分别用0和1表示Similarly
h_n:(num_layers * num_directions, batch, hidden_size),
只会输出最后个time step的隐状态结果(如下图所示)。
Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size) and similarly for c_n.
c_n :(num_layers * num_directions, batch, hidden_size),只会输出最后个time step的cell状态结果(如下图所示)。
5. 参考文档
- https://www.zhihu.com/question/41949741/answer/318771336